The Brown Neurosurgery Department recently published two preprints comparing the performances of Artificial Intelligence Large Language Models ChatGPT, GPT-4 and Google Bard in the neurosurgery written board examinations and the neurosurgery oral board preparatory question bank.
They found that these AI models were able to pass the written exams with “flying colors.” When challenged to answer the more complicated oral exam questions, which require higher-order thinking based on clinical experience and exposure, the models still performed “superbly,” said Ziya Gokaslan, professor and chair of neurosurgery at the Warren Alpert Medical School and neurosurgeon-in-chief at Rhode Island Hospital and The Miriam Hospital.
Since its publication, the preprint focused on the oral board exam questions has ranked in the 99th percentile of the Altmetric Attention Score, which has tracked the amount of attention received by over 23 million online research outputs.
“It’s such an exploding story in the world and in medicine,” said Warren Alpert Professor of Neurosurgery Albert Telfeian, who is also the director of minimally invasive endoscopic spine surgery at RIH and director of pediatric neurosurgery at Hasbro Children’s Hospital.
Inspiration for the study and key findings
The project was inspired when fifth-year Neurosurgery Resident and Co-first author Rohaid Ali was studying for his neurosurgery board exam with his close friend from Stanford Medical School, Ian Connolly, another co-first author and 4th year neurosurgery resident at Massachusetts General Hospital. They had seen that ChatGPT was able to pass other standardized exams like the bar examination, and wanted to test whether ChatGPT could answer any of the questions on their exam.
This prompted Ali and Connolly to execute these studies in collaboration with their third co-first author, Oliver Tang ’19 MD’23. They found that GPT-4 was “better than the average human test taker” and ChatGPT and Google Bard were at the “level of the average neurosurgery resident who took these mock exams,” Ali said.
“One of the most interesting aspects” of the study was the comparison between the AI models, as there have been “very few structured head-to-head comparisons of (them) in any fields,” said Wael Asaad, associate professor of neurosurgery and neuroscience at Warren Alpert and director of the functional epilepsy and neurosurgery program at RIH. The findings are “really exciting beyond just neurosurgery,” he added.
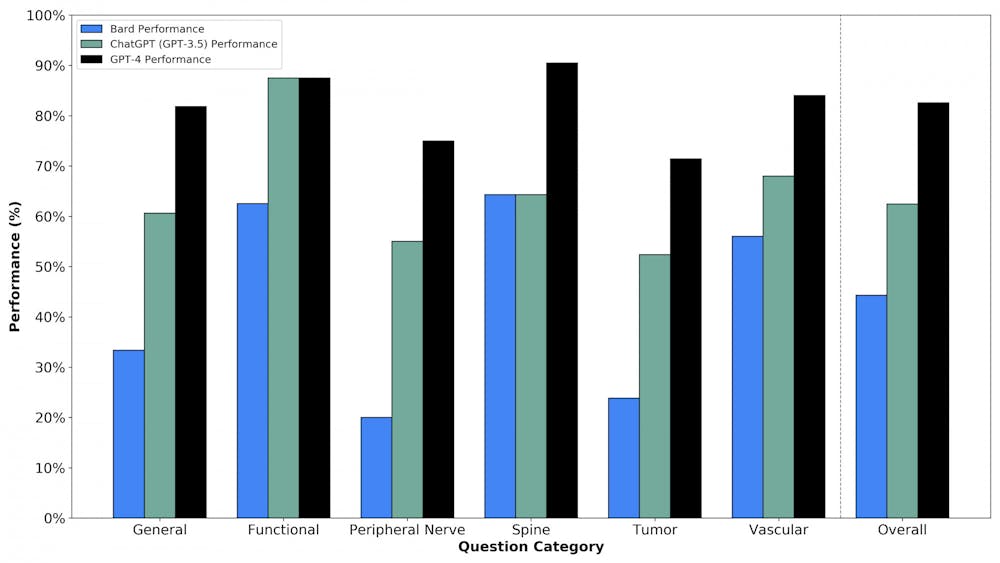
The article found that GPT-4 outperformed the other LLMs, receiving a score of 82.6% on a series of higher-order case management scenarios presented in mock neurosurgery oral board exam questions.
Asaad noted that GPT-4 was expected to outperform ChatGPT — which came out before GPT-4 — as well as Google Bard. “Google sort of rushed to jump in and … that rush shows in the sense that (Google Bard) doesn’t perform nearly as well.”
But these models still have limitations: As text-based models cannot see images, they scored significantly lower in imaging-related questions that require higher-order reasoning. They also asserted false facts, referred to as “hallucinations," in answers to these questions.
One question, for example, presented an image of a highlighted portion of an arm and asked which nerve innervated the sensory distribution in the area. GPT-4 correctly assessed that it could not answer the question because it is a text-based model and could not view the image, while Google Bard responded with an answer that was “completely made up,” Ali said.
“It’s important to address the viral social media attention that these (models) have gained, which suggest that (they) could be a brain surgeon, but also important to clarify that these models are not yet ready for primetime and should not be considered a replacement for human activities currently,” Ali added. “As neurosurgeons, it’s crucial that we safely integrate AI models for patient usage and actively investigate their blind spots to ensure the best possible care for the patients.”
Asaad added that in real clinical scenarios, neurosurgeons could receive misleading or irrelevant information. The LLMs “don’t perform very well in these real-world scenarios that are more open-ended and less clear cut,” he said.
Ethical considerations with medicine and AI
There were also instances where the AI model’s correct response to certain scenarios surprised the researchers.
For one question about a severe gunshot injury to the head, the answer was that there is likely no surgical intervention that would meaningfully alter the trajectory of the disease course. “Fascinatingly, these AI chatbots were willing to select that answer,” Ali said.
“That’s something that we didn’t expect (and) something that’s worth considering,” Ali said. “If these AI models were going to be giving us ethical recommendations in this area, what implications does that have for our field or field of medicine more broadly?”
Another concern is that these models are trained on data from clinical trials that have historically underrepresented certain disadvantaged communities. “We must be vigilant about potential risks of propagating health disparities and address these biases … to prevent harmful recommendations,” Ali said.
Asaad added that “it’s not something that’s unique to those systems — a lot of humans have bias — so it’s just a matter of trying to understand that bias and engineer it out of the system.”
Telfeian also addressed the importance of human connections between doctors and patients that AI models still lack. “If your doctor established some common ground with you — to say ‘oh, you’re from here, or you went to this school’ — then suddenly you’re more willing to accept what they would recommend,” he said.
“Taking the surgeon out of the equation is not in the foreseeable future,” said Curt Doberstein, professor of neurosurgery at Warren Alpert and director of cerebrovascular surgery at RIH. “I see (AI) as a great aid to both patients and physicians, but there are just a lot of capabilities that don’t exist yet.”
Future of AI in medicine
With regard to the future of AI models in medicine, Asaad predicted that “the human factor will slowly be dialed back, and anybody who doesn't see it that way, who thinks that there’s something magical about what humans do … is missing the deeper picture of what it means to have intelligence."
“Intelligence isn’t magic. It’s just a process that we are beginning to learn how to replicate in artificial systems,” Asaad said.
Asaad also said that he sees future applications of AI in serving as assistants to medical providers.
Because the field of medicine is rapidly advancing, it is difficult for providers to keep up with new developments that would help them evaluate cases, he said. AI models could “give you ideas or resources that are relevant to the problem that you’re facing clinically.”
Doberstein also noted the role of AI assisting with patient documentation and communication to help alleviate provider burnout, increase patient safety and promote doctor-patient interactions.
Gokaslan added that “there’s no question that these systems will find their way into medicine and surgery, and I think they’re going to be extremely helpful, but I think we need to be careful in testing these effectively and using it thoughtfully.”
“We’re at the tip of the iceberg — these things just came out,” Doberstein said. “It’s going to be a process where everybody in science is going to constantly have to learn and adapt to all the new technology and changes that come about.”
“That’s the exciting part,” Doberstein added.
Gabriella was a Science & Research editor at The Herald.


